
Hành trình trở thành một thám tử chuyên nghiệp của một developer.
Bạn là một developer đang tìm kiếm sự hoàn hảo cho phần mềm của mình. Phần mềm của bạn ngày càng lớn và bạn không để kiểm soát hết được hiệu năng hệ thống của bạn.
Nhất cử nhất động của hệ thống bạn phải nắm được toàn bộ. Nó khỏe yếu, ho hay cảm cúm, nó đi những đâu, trong thời gian như thế nào thì chúng ta đều phải nắm được
Trước tiên, chúng ta phải hiểu một hệ thống phân tán là gì?
Hệ thống phân tán về cơ bản là một mạng gô các hệ thống/ máy chủ độc lập được kết nối bằng phần mềm trung gian có thể chia sẻ tài nguyên. Mục tiêu là làm toàn bộ mạng phân tán hoạt động như một ứng dụng duy nhất
Lập trình hệ phân tán là nghệ thuật giải quyết cùng một vấn đề mà bạn có thể giải quyết trên một máy tính nhưng lại sử dụng nhiều máy tính - Mikito Takada
Các dịch vụ hiện đại thường được triển khai dưới dạng một hệ thống phân tán phức tạp, quy mô lớn. Các hệ thống có thể được phát triển bởi những nhóm khác nhau, công nghệ, ngôn ngữ khác nhau, và có thể trải rộng trên hàng trăm máy chủ phân tán. Các công cụ giúp developer và devops hiểu rõ các hành vi của hệ thống và suy luận về các vấn đề hiệu suất là vô giá trong các môi trường như vậy.
Trong bài viết này mình giới thiệu về concept của Dapper - một nền tảng theo dõi hệ thống phân tán quy mô lớn của Google.
Dapper có hai yêu cầu cơ bản ubiquitous deployment and continous monitoring (triển khai trên toàn bộ hệ tống và giám sát liên tục). Những yêu cầu đối với hệ thống Dapper:
- Low overhead (Chi phí thấp): Công cụ theo dõi sẽ không có ảnh hưởng hoặc ảnh hưởng rất nhỏ đến các dịch vụ được triển khai
- Application-level transparency (tính trong suốt): nhà phát triển/ người dùng không cần quan tâm sự tồn tại của hệ thống tracing
- Scalability (khả năng mở rộng): có khả năng xử lý quy mô lớn các service độc lập với nhau
- Analysis quickly (phân tích nhanh chóng)
Distributed Tracing in Dapper
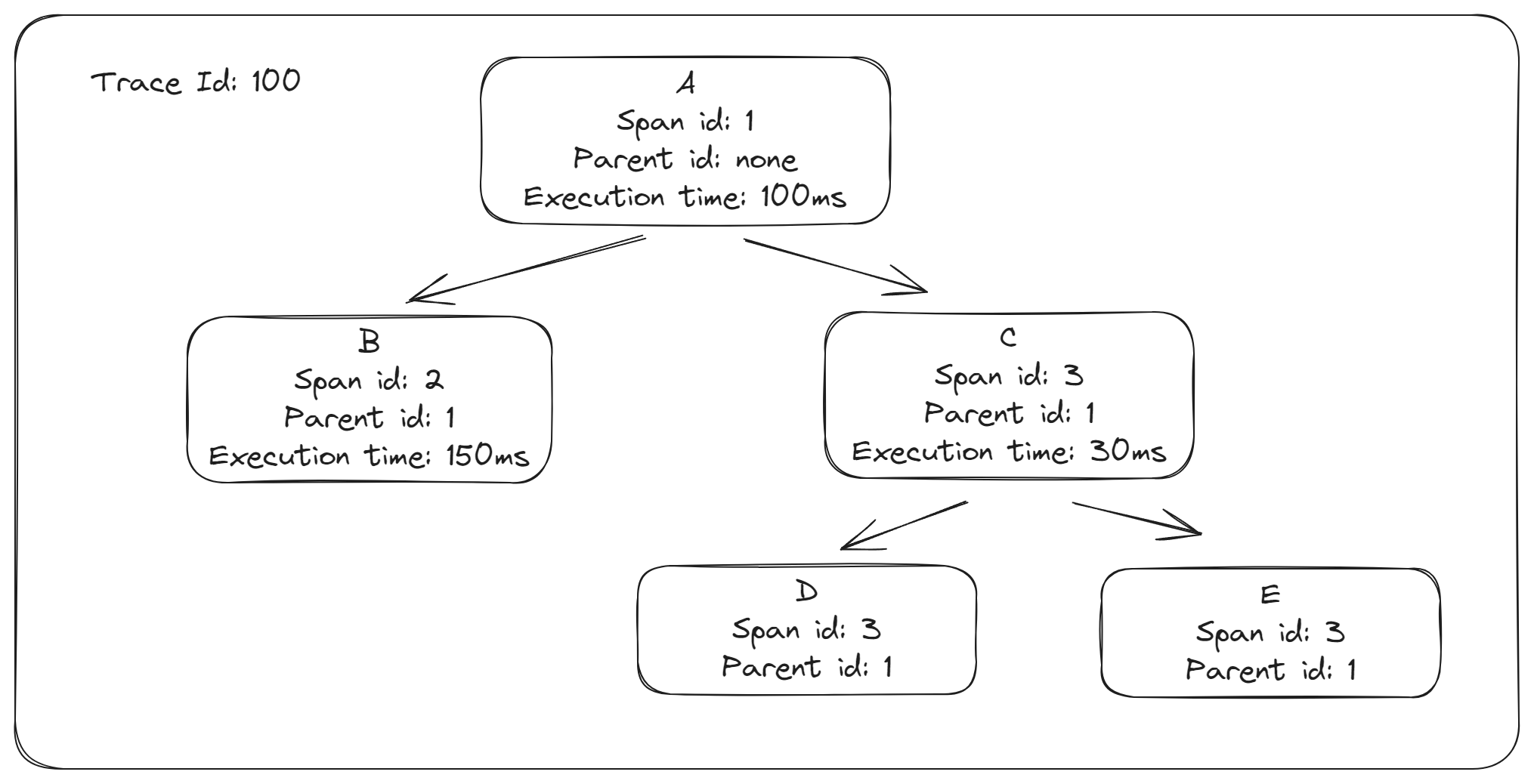
Một hệ thống theo dõi cần lưu lại những thông tin tại từng server và chuyển tiếp những thông tin đó đến các server tiếp theo.

Trong mô hình trên, chúng ta có 5 server. Khi người dùng gửi một request đến frontend A , nó gửi 2 yêu cầu RPC đến server B và C. Sau ó, B trả về kết quả luôn cho A còn lại C sẽ tiếp tục gửi yêu cầu RPC đến D và E trước khi gửi lại cho A.
Để theo dõi một cách đơn giản hệ thống này, chúng ta cần một tập hợp các số nhận dạng từng request (yêu cầu) các các sự kiện phải được đánh dấu thời gian cho mỗi request được gửi và nhận tại mỗi service.
Trace trees and spans
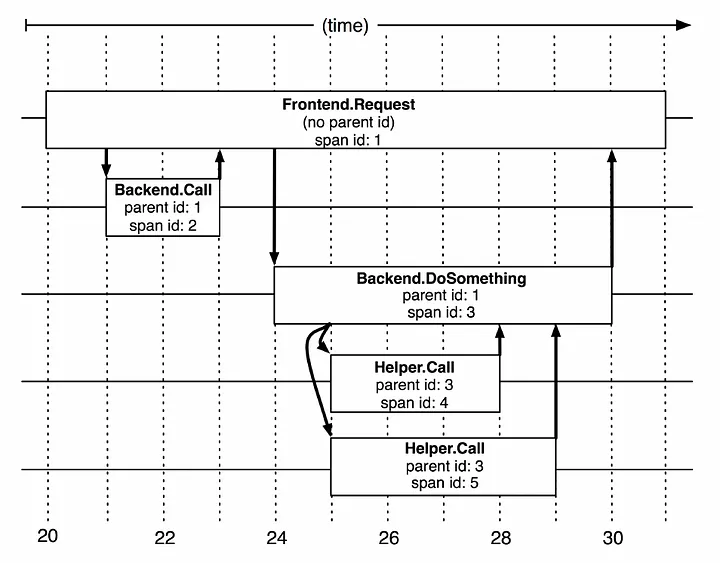
Để hiểu về các hình ảnh, chúng ta có một số khái niệm
- Span: một đơn vị công việc cơ bản thực hiện một yêu cầu hoặc giao dịch của người dùng.
- Trace: một cây các span
Sơ đồ trên biểu diễn 1 luồng thực hiện tracing sẽ diễn ra như thế nào.
Dapper ghi lại thông tin trên từng span bao gồm span id và parent id. Span được tạo mà không có parent id thì được hiểu là span gốc (root span).
Tất cả span trong một luồng (flow) duy nhất đều chung 1 trace id.
Tất cả được tóm gọn lại trong sơ đồ sau
Trace colllection
Quy trình ghi nhật ký, thu thập dữ liệu tracing được thể hiện bằng 3 giai đoạn trong hình dưới đây:

- Span data được lưu trữ trong file log của từng service
- Sau đó sẽ được Dapper deamon thu thập
- Cuối cùng dữ liệu thu thập được sẽ được ghi vào bảng theo trace id và từng span id
Dữ liệu cuối cùng sẽ được phân tích và hiển thị trên giao diện của nhà quản trị dựa vào bảng dữ liệu đã có sẵn. Trong Spring Boot, việc thu thập và xử lý dữ liệu có thể được thực hiện bằng các thư viện ví dụ như: micrometer-tracing, sleuth, ... và các công cụ Zipkin, Jaeger,...
Tổng kết
Bài này mình viết về Dapper chủ yếu là tổng hợp lại những gì mình tìm kiểu (mình thì chủ yếu làm về Java chứ không phải C++). Tuy nhiên, kiến thức về Dapper sẽ giúp chúng ta hiểu rõ hơn về cách cách hệ thống tracing hoạt động (micrometer-tracing + zipkin hoạt động cũng tương tự như thế).
Có một số người nói đã là dev thì cần gì quan tâm vận hành hệ thống như thế nào cho mệt đầu. Tuy nhiên đối với mình thì mình không cho là đúng. Theo mình, kinh nghiệm vận hành và tư duy hệ thống sẽ giúp chúng ta hiểu hơn về hệ thống, fix lỗi nhanh hơn, ... sẽ tạo ra một sự khác biệt thú vị trong công việc dev nhàm chán này.
Hãy đọc và để lại ý kiến cho mình qua mail [email protected].
Bye!